浅谈代码架构设计

老Y是一个有着十多年经验的软件开发工程师。下面是老Y和代码架构设计有关的故事。
在软件开发者的职业生涯当中,一定会遇到大量关于代码架构方面的名词,比如“可维护性”、“可扩展性”、“高内聚低耦合”、“组件化”、“分层架构”、“SOLID”等等。在短短几十年的计算机历史中,涌现了大量有关软件架构的经典著作,对架构进行了极其全面又深入的讨论,这些著作基本来自于在软件行业有着数十年经验的大神们。既然已经有了这些全面、系统、深入的架构著作,为什么还要写这篇文章?
从小有句话我们可能听了无数遍——实践是检验真理的唯一标准。即使读过了这些著作,听了大神们的分享,我们依然不能说自己掌握了软件架构的设计。好似那些自己不亲自踩过坑就无法懂得的道理一般,只有在编码的道路上不断实践,不断将理论与实践结合,才能够做到真正的掌握。所以本文仅站在一个普通软件开发者的角度,从架构设计上的一些经历和踩过的坑出发,来谈谈代码设计,讨论在追求更好的架构设计道路上的那些痛苦与挣扎,以及豁然开朗的时刻。
老Y说:在写代码的路上,始终要记得一点,“代码是给人看的,而不是机器”,所以那些奇技淫巧并不推荐。
目录
井底之蛙
老Y在大学时是电信专业,和编程有关的课程只有C和C++,C++还是一门选修课,对于网络、操作系统等全然不知,一直以为学好C/C++,有一定的逻辑思维,就算是进入了软件开发行业的大门。彼时写的代码都是一个个允长却又逻辑简单的函数,像是用编程语言写的菜谱。
数千行的main
估计和很多人一样,老Y在学校做过最大的项目是毕业设计,选题是基于计算机视觉的交通流量检测系统。在有了方案后,老Y根本没想着要如何去设计这套系统,而是“文思泉涌”般立刻开始编码。因为其中要运用大量的算法,处理流程也非常长,所以最终的代码量有数千行。但那时老Y在开发上并没有模块的概念,所以整个代码库只有一个main.cpp文件,几千行代码堆满其中。文件中充满了无数的函数、全局变量,老Y根本不知道什么是设计,它就像是逻辑的自然倾泻,也只有老Y自己才能看明白,可维护性极差。后来他才知道,这种编码还有一个名称,叫过程式编程。老Y甚至还把C++当成C语言来使用,摒弃面向对象特性。
虽说代码写的很差,但在这次的毕设过程中,老Y对软件开发有了初步的认识。“程序=数据结构+算法”,忘了在哪里看过的说法,这次他对这句话颇有理解。因为毕设项目中需要运用大量的算法,所以老Y寻找了很多的论文,并实现其中的算法。为了让算法能够更容易传递数据,老Y也运用了多种数据结构,最后好像整个项目都由它们构成。记得一次和老Z去吃饭的路上,老Y说这时候才理解“程序=数据结构+算法”。不过现在看来,这句话是在一定的语境下出现,存在片面性。
MFC启蒙
大部分软件开发都离不开GUI,而老Y最初接触的GUI框架是MFC(Microsoft Foundation Class),估计很多人都没听过,它曾是微软关于Windows编程的官方C++ GUI库,集成在Visual Studio中,就好比现在UIKit集成在Xcode中一样。MFC可能是很多人了解架构的启蒙,老Y也不例外。
在新建工程时,MFC会默认创建CDocument、CFrame、CApp等文件,开发者只需依葫芦画瓢,在不同地方填写不同的代码即可。但在使用了很长时间后,老Y也没理解为什么要这么划分,反而认为这样散落在不同文件中的设计,充满了诸多不便。而且MFC中包含了大量tricky的宏定义,导致对其运行机制的理解更是难上加难。
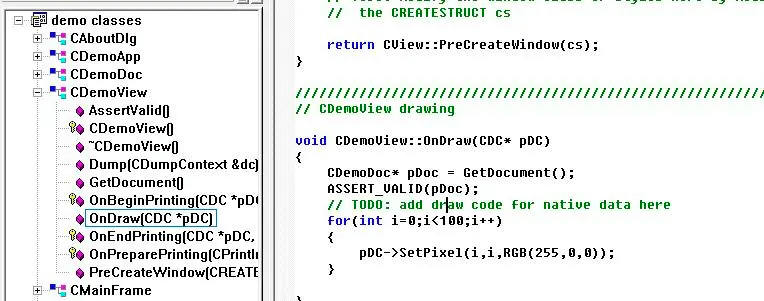
直到老Y后来读了侯捷的《深入浅出MFC》,才知道MFC设计的精妙。即使现在MFC已经退出历史舞台,但它不失为学习架构设计的一个非常好的例子,作为微软的官方GUI库,它也在软件开发的历史上留下了浓墨重彩的一笔。顺便一说,侯捷写/译了大量关于C++的经典著作,尤其擅长源码剖析,比如《STL源码剖析》、《Effective C++》、《深度探索C++面向对象模型》(老Y曾被这本书折磨的死去活来),可以说是在C++能够在中国传播最重要的人物,任何一个深入学习过C++的软件开发者可能都听过他的名字。老Y也是在读完《STL源码剖析》之后,写下了知无涯之std::sort源码剖析。
MVC or MFC
老Y在毕业找工作时经历过一次印象深刻的面试,面试官问,MVC是什么?大家可能觉得这是送分题,老Y当时却为他的浅薄无知付出了代价。他大言不惭的想,是不是面试官说错了,应该是MFC吧,并且真的把自己的想法说了出来,现在每每回忆起来都觉得无比尴尬,不知道面试官当时内心活动是什么,只会觉得这傻小子无知且迷之自信吧。但可能是其它方面打动了面试官,最后老Y拿到了这家互联网公司的offer。
那是第一次有人问老Y代码设计的问题,过去更多是问算法、数据结构等计算机基础。老Y在准备面试的过程中,也从来没准备过相关问题,这才闹了笑话。
老Y说:无论校招还是社招,面试都会看整体表现,不会因为一两个问题没回答好而不通过。
初出茅庐
老Y毕业后,加入那家面试时问MVC的互联网公司,做移动端视频App开发。此时老Y已经有了初步的模块意识,会将不同功能放在不同文件中,而不是像毕设时将所有的代码堆在一个文件。这么多年过去,有一个项目中的源代码老Y还时常回忆起,叫movie_data.c,它相当于MVC中的model层,作者就是老Y。
从文件命名中可以看出,它用于处理视频的数据,包含多种场景,从服务端请求、到xml解析、到model的转换等。老Y还清晰的记得当时每个场景的函数,都是一个长达十几种条件分支的巨大switch case,每个场景都有着类似的代码结构。
// movie_data.c
void function1() {
...
switch (type) {
case A: {
}
case B: {
}
...
case Z: {
}
}
}
void function2() {
...
switch (type) {
case A: {
}
case B: {
}
...
case Z: {
}
}
}
...
void functionN() {
...
switch (type) {
case A: {
}
case B: {
}
...
case Z: {
}
}
}
相信你已经可以看出这里的问题,老Y在当时已经觉得写起来很奇怪,不仅每个函数允长,且存在大量重复的分支逻辑。改动起来也很痛苦,每增加一个type,就得所有的方法都加一条case语句。但当时由于开发时间紧张,又没有任何架构设计方面的理论支撑,老Y并不知道如何优化。现在回头来看,一切显得那么简单。可以将同一类型的处理封装到一个模块中(那时用的是C,没有class),然后再根据不同的场景类型来注册handler即可。这是老Y首次在工作中意识到除了有数据结构和算法以外,还有架构。
老Y说:每个人都是如此摸爬滚打成长的,时刻处于无知与更大的无知之中。
读万卷书
代码大全
后来老Y加入了一家外企,因为节奏比互联网慢很多,所以老Y便利用空闲时间,恶补了大量本应在学校期间就掌握的知识,将各个领域的经典著作看了一个遍,这其中就包含了对他影响最大的《代码大全》。除了感叹于它的大而全,其中印象最深的有三点:
- 代码设计就是管理复杂度
- 表驱动法
- DRY原则
第一点管理复杂度,如上面的movie_data.c,它将处理type的复杂度暴露给了每个场景的方法,所以每个场景都需要去switch case一番。再如毕设期间长达几千行的main.cpp,也是因为复杂度过高,所以需要将它拆到不同的模块中去。移动端开发的MVC、MVVM等,将模块抽象成Model、View、Controller等,都是期望降低某一个模块的复杂度,在一个模块进行修改时,不需要感知其它模块。代码中的入参也同样,超过了一定的数量后,如7个,那么就需要考虑将它们放在不同的结构中了。甚至一切设计模式都是用于管理软件复杂度的手段。
第二点是表驱动法,这是一个至今依然在大量使用且极其高效的方法。还是以movie_data举例,可以将每个场景的处理封装到对应的方法中,然后通过表查询来处理:
// movie_data.c
void registerHandlers() {
handler1Map = { // 将类型与对应的处理封装到字典中,使用时直接通过类型查到对应的handler
A: handler1A,
B: handler1B,
...
Z: handler1Z
};
handler2Map = {
A: handler2A,
B: handler2B,
...
Z: handler2Z
};
...
handlerNMap = {
A: handlerNA,
B: handlerNB,
...
Z: handlerNZ
};
}
void function1() {
Handler handler = handler1Map[type];
handler();
}
void function2() {
Handler handler = handler2Map[type];
handler();
}
...
void functionN() {
Handler handler = handlerNMap[type];
handler();
}
可以看到,上面的代码清晰了很多。每个场景的funciton不再需要去处理switch case的逻辑,所有的switch case都通过表查询handler1Map[type]解决,函数内部的复杂度立刻降了下来。
甚至可以进一步的将同一种类型的处理进行封装,以减少不同类型之间的耦合。
// modelA.c
void registerAHandlers() {
// 所有A相关的处理都位于该模块中,对其它类型都不感知
handlerA[] = [
handler1A,
handler2A,
...
handlerNA
];
}
...
// modelZ.c
void registerZHandlers() {
handlerZ[] = [
handler1Z,
handler2Z,
...
handlerNZ
];
}
// movie_data.c
void registerHandlers() {
handlersMap = {
A: handlerA,
B: handlerB,
...
Z: handlerZ
};
}
void function1() {
Handlers handlers = handlerMap[type];
Handler handler = handlers[0];
handler();
}
void function2() {
Handlers handlers = handlerMap[type];
Handler handler = handlers[1];
handler();
}
...
void functionN() {
Handlers handlers = handlerMap[type];
Handler handler = handlers[2];
handler();
}
再进一步的优化可以在拿到数据后立刻获取该类型的所有handlers,后续所有的function中不再传递type,而是直接传递handlers。如果是面向对象语言,可以在创建多个子类,然后由工厂方法根据type创建一个子类的实例。
对本书印象较深的第三点是DRY原则,大家可能都听过它,Don’t Repeat Yourself,字面意思非常简单,不要重复。重复的意思可以有很多种,比如不要有重复的代码,强调代码的可复用性。工作中有很多这样的场景,要新开发一个功能,发现之前有人写过类似的方法,那么是直接快速拷贝一份代码,改几行?还是对方法进行抽象,将可复用的部分下沉,提取出参数来区分不同的逻辑?同样运用到上面的movie_data中,前期的movie_data每个场景都有大量的switch case语句,每次进到一个函数中都要处理一轮,重复的逻辑处理。
DRY并不一定是在开发过程中才经常用的原则,它也可以用到其它场合。老Y有段时间需要在一个App上查询社康是否有某个疫苗,查询了全市很多社康都找不到,因为很着急打这个疫苗,所以他连续每天都要搜索一遍。操作不算复杂,但就是比较繁琐,App不支持查询功能,需要手动切换社康查看。为了避免每一次的手动操作,老Y花了大约一天的时间写了个爬虫,每天定时将全市的社康都查一轮。这两种处理方式的总耗时可能差不多,也许写爬虫还会多一些,但其中的思维却有着比较大的差异。
老Y说:最后再强烈推荐大家去读一读这本900多页的“砖头”,以上的介绍不及此书的万分之一,作者不仅把软件开发的方方面面讲了个遍,并且文笔极好,读起来十分顺畅。
重构
除《代码大全》以外,老Y在此期间还读了大量设计模式相关的书,比如四人帮的《设计模式》、《重构》、《代码整洁之道》、《HeadFirst设计模式》等,积累了很多关于代码设计的理论知识。
在所有这些书中,老Y印象最深的是在《重构》中读到的“坏味道”。如果让我们说出一道菜为什么好,可能会有点难度,但如果让我们说出一道菜哪里不好,那可就容易多了,可能这是人类的天性,我们对于找茬更加擅长,对坏味道可能比好味道更加敏感,而当我们发现这道菜中的所有坏味道并一一去除,这道菜便离美味不远了。代码亦是如此,如果熟悉了这些原则,在实践中不断训练自己找到代码中“坏味道”的能力,发现之后,再尝试用这些原则与模式对其进行重构,写出好代码的可能性便大大提升。
老Y说:23个设计模式是“术”,是手段,7大设计原则是“道”,掌握它们之后,想要进行架构设计还需要知道力该往哪里使,于是需要找出“坏味道”的“嗅觉”。最后再加上一点“洁癖”,这是动力。
行万里路
纸上谈来终觉浅,觉知此事要躬行。有了大量的理论“锤子”支撑之后,老Y便开始寻找一切能看到的“钉子”,开始了行万里路的阶段。
理解抽象
在所有降低代码复杂度的方法中,抽象也许是最重要的一个,甚至可以说软件的本质就是抽象。我们平常会抽象出来各种函数、类、数据结构,其核心目的依然是为了降低复杂度。
整个软件开发都是在做抽象,从底层往上层看,高级语言是对汇编的抽象,降低对汇编理解的复杂度;高级语言提供的标准库,它是抽象出来降低开发者对底层的复杂度;网络模型是抽象,它用七层抽象依次将上一层的复杂度控制在一定范围内;基础库是抽象,比如网络库将网络相关的能力基于网络模型进行封装,降低了网络使用的复杂度;业务模块开发也是抽象,业务代码经常会划分为原子能力层、组件层、业务层等,理想状态下每一层都只会与它下一个层级打交道,从而极大的降低每一层的复杂度。
同样,不管是设计原则还是设计模式本质上是讲如何做抽象,比如前面提到的DRY原则,目的就是将重复的部分抽象成可复用的逻辑,让每一个上层仅关心这个复用逻辑即可。前面提到的表驱动法也同样,它将switch case抽象到了一个字典中,使每个场景不用去关心不同type的分支逻辑。
在这家外企,老Y通过几个项目对抽象有了进一步的理解。
老Y说:软件开发目标是降低复杂度,一切手段的本质是抽象。
日志系统
首先是日志系统,它是每个软件中必不可少的基石。读到这里,先停一下,如果要你要来设计一个日志系统时,你会怎么做?
之前老Y写过一篇文章来探讨日志,从0开始一步步搭建起日志系统。它从简单的printf出发,逐步增加需求,在一个个问题得解决之后,便抽象出很多概念,比如TraceLevel、Marker、Appender、Formatter、Category等。这看起来非常复杂,增加了开发者的理解成本,但当其背后的思考在揭示之后,你便可以理解它的强大。正是这些概念的引入,使得日志系统能够满足各种需求,且能够帮助开发者方便的进行扩展。Python的logging设计也是类似。
值得注意的是,它们并不是一开始就设计成这样,而是随着需求的增加,一步步抽象而成。软件开发并不提倡过度设计,它提倡的是最高效的满足当下需求的同时,又具备较好的可维护性与扩展性。比如如果是写一个控制台的demo,直接用printf就够了,不需要引入那么复杂的概念。
下图是核磁共振设备上运行了几十年的日志系统,这也是老Y迄今为止遇到最为复杂的日志设计。它不仅有一个总的日志文件,每个模块还有各自的日志,同时左边是一台Windows,右边是一台Linux,两者可以完美的协作,并可以在Windows上实时的查看Linux上的运行日志。这其中大量的运用了观察者模式,如Appender。更多细节可以在深入理解log机制一文找到。
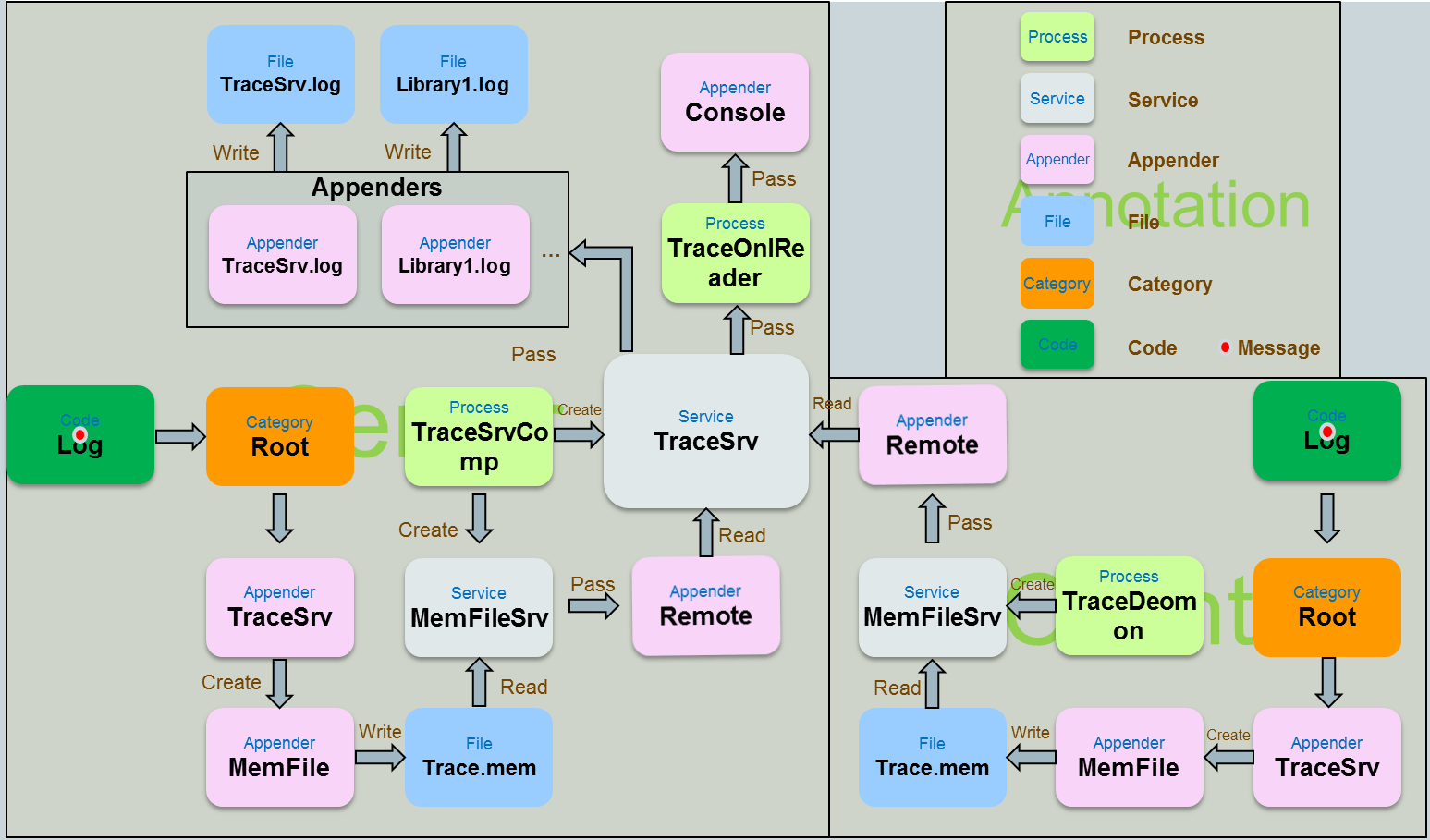
老Y说:类似于上图的系统看起来极其复杂,直接去看代码肯定会懵掉,在理解各种概念之后再去阅读源码,一切会变得简单很多。
单元测试
单元测试框架也是每个语言所必不可少的组成部分,它为单元测试提供了最重要的支持。同样,在这里停下来思考一下,如果要你来设计单元测试框架,你会如何做?
熟悉它的同学可能会了解到框架中同样抽象了大量的概念,比如TestSuite、TestCase、TestRunner、TestResult等,而且这些概念在几乎所有语言的单元测试框架都类似,比如Java的JUnit、C++的CppUnit、Xcode的XCTest等,原因是它们都源自于同一个库,JUnit(再往前可延伸到SmallTalk的测试框架)。可以看看它的作者,Kent Beck与Erich Gamma(后者是《设计模式》一书的作者、Eclipse的作者、vscode的作者),《代码整洁之道》的第十五章《JUnit内幕》讲述了框架设计背后的故事,两位大神竟然是在一次3小时的飞机旅程中写出了这个框架。
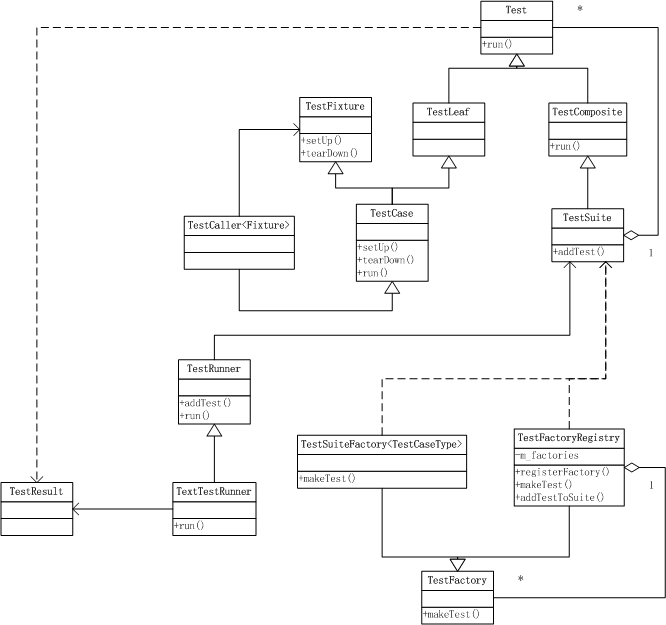
上面是它的类继承关系图,每个类都有其单一的职责,并运用组合与继承,结合在一起:
- TestCase是一个具体的测试用例
- TestSuite是多个TestCase的组合
- TestRunner负责运行所有的Test/TestSuite
- TestFactory是一个创建工厂等
从图上也可以看出这里运用了几种设计模式:
- TestSuite是组合模式,将TestCase组装成一个树状结构
- TestFactory工厂模式
- 另外还有未画出来的结果通知,采用了观察者模式
小结
以上两个系统都是短小精干的代码库,读起来很快,画几个UML图就可以非常容易的理解它们的设计。它们娴熟的运用了各种设计原则与模式(毕竟其中之一是设计模式的作者对吧),读完定有收获。
多媒体缓存
好的命名是成功的一半
如果说软件开发中什么最难,命名可能首当其冲。相信大家都有过被各种仓库、类、函数、变量命名折磨过的经历,老Y也不例外。这里想讲述一段老Y有关命名的经历,看起来只是一个命名的问题,实际上不同的命名让整个代码的作用有着完全不同的解释。
老Y当时面临的问题是要重构支付宝App中的多媒体缓存,这个库要处理包含文件、图片、语音、视频等多媒体资源的缓存。这里有一个逻辑很复杂,每个资源有两个id,一个叫做cloudId,它是该资源在服务端的id,可以用这个id去下载对应的资源。另外还有一个id叫localId,它是资源在上传之前,存储于本地的id,比如对相册中的图片进行压缩之后,会放入缓存中,需要一个key来获取该资源,这个key就是localId,表示其在本地的资源id,等到上传完成后,会从服务端获取一个对应的资源id,即cloudId,最终被关联到本地的缓存资源中。业务侧可以用这两个id中的任何一个来获取缓存资源。原有的存储与查询接口都分别有localId与cloudId的不同API,给使用方也带来了一定的理解成本。
读到这里你是否嗅出了很重的“坏味道”?
随着业务对缓存使用的复杂度越来越高,原有的缓存面临着重构,设计数据库的字段与缓存接口时,无论如何老Y都接受不了这两个命名,localId与cloudId,总觉得它们很奇怪,带有太强的实现细节。老Y认为一个更好的设计是不应该暴露内部的实现细节。而且作为一个缓存库,不应该理解local与cloud的概念,所有存储的内容在缓存这个抽象层就仅仅是一个资源而已,local与cloud属于更上层的业务逻辑。所以他反复拉着同事讨论,这两个字段也迟迟未能确定下来。
如何让一个缓存资源能够被两个不同的id找到?如何在缓存资源中将这两个id关联起来?这就成了老Y设计时考虑非常久的问题,如果这个问题不解决,重构再往前推进也面临着很大的困难,老Y认为这里是设计的关键所在,它也决定着底层的数据库设计,所以并不仅是一个名字那么简单。
念念不忘,必有回想。近一周后的一天,老Y灵光一闪,想到了Linux Shell中的alias,它可以为一个命令创建别名,无论是输入别名还是原有的命令,都表示同一个意思。老Y想,这里原来的localId与cloudId是否可以采用同样的方式,互为别名,老Y为自己的这个想法拍案叫绝。因此就有了这样的数据库字段设计:key作为资源的常规标识,同时增加一个叫alias_key的字段,作为该资源的别名,与key有同等作用。如此一来,下载资源时,资源会以key存在在缓存中,这里是key即原有的cloudId字段。在上传时,处理完的相册图片可以采用key来存储资源,即原有的localId字段。在上传成功后,要关联服务端返回的cloudId时,就可以将cloudId设置到alias_key的字段。这样不管是数据库,还是接口,都对业务层的逻辑不再感知,不管是local或者是cloud,缓存只认key和alias_key,相当于通过提供alias的能力,让缓存能够处理原有的localId与cloudId,看起来优雅了很多。
接口设计上也只有根据key来查询资源或者存储资源的接口,同时增加设置别名的接口,用于关联两个key,仅此而已。使用key还是alias_key去查询,这些逻辑全都被封装在缓存的内部进行处理,业务侧不再需要考虑这个key是local还是cloud,极大的简化了接口,方便了业务侧的使用。
在突破了这个“难题”之后,后续的设计就变得简单起来,老Y也一气呵成完成了整个多媒体缓存的设计。后面也果然遇到另外的需求也需要两个key,而且不再是localI与cloudId。需求是当一个用户替换了头像,在新头像下载完成之前采用旧的头像,此时可以用这一套缓存很方便的解决,即可以给旧头像设置alias_key,当新头像未能下载成功时,缓存会从alias_key中去查找到旧头像,于是快速的实现了这个需求,甚至不用修改一行代码。
这个命名问题给老Y留下了很深的印象,让他坚信对命名的坚持是有意义的,而且它不仅是一个名称的问题,而是可能左右整个设计的关键,它决定了设计抽象的好坏。
老Y说:如果没有经历过命名上的绞尽脑汁,可能也永远无法体会想出一个合适名字时的愉悦感。
责任链
继续多媒体缓存的设计,除了命名以外,老Y还有一个印象深刻的设计问题。
图像缓存的查找在多媒体图像业务中占据着核心的位置,所有看到图片的地方都离不开它,它的性能左右着整体产品的体验。可以想象如果在刷小红书时,图片卡顿对体验造成的负面影响。
图像查询的逻辑也极其复杂,大致存在这样的查询顺序:对应图像的q值->等比图->原图->大图->其它更大尺寸需裁剪的图->图像key的别名等,由前向后,当前的条件不满足时fallback到下一个,当用原来的key没查到时,需要再用alias_key重新查一轮,没有精确的查询到时还需要找到比它大的图再进行裁剪处理。这里再停顿一下,如果是你,你会怎么写这段查询逻辑?
直观的写法是采用一个巨大的查询逻辑,依次按照上面的顺序进行查询,这里是否又嗅到了“坏味道”?
Image *getImage(char *key, Size size, int qValue) {
Image *cache = getCache(key, size, qValue);
if (cache == NULL) {
cache = getCacheWithAliasKey(key, size, qValue);
if (cache == NULL) {
cache = getScacledImage(key, size);
if (cache) {
// crop image
} else {
cache = getOriginalImage(key, size);
if (cache) {
// crop image
} else {
cache = getBigImage(key, size);
...
}
}
}
}
return cache;
}
上面的代码可以看到查询逻辑非常复杂,每个查询的代码会受到其它查询的影响。该方法本身已经足够臃肿,如果要调整查询顺序时都需要在该方法中去修改,容易出错。这样将导致代码极难维护,且难以扩展。
我们来看怎么对这个问题进行抽象,这里的每一个查询可以作为一个单独的类/方法,它们不需要关心其它的查询是怎么进行的,只需要给定入参,并返回一个结果即可,所以可以抽象成一个查询类,每个查询都对应着一个子类。而查询像是一个链条一样,当前查询完成之后,如果未完成就进行下一步的查询,直到所有的步骤都完成后,返回结果即可,老Y想起设计模式中的责任链模式。在图像缓存创建时,将这个责任链组装起来,后续所有的查询只需过一遍责任链。从扩展性上来说,调整某个查询的逻辑时只需要在对应的查询子类中处理,不影响其它的查询。如果要修改查询顺序或者增加新的查询,只需在构建责任链时处理。
class Querier {
public:
Image *query(char *key, Size size, int qValue) {
Image *image = getCache(key, size, qValue);
if (image == NULL) {
image = getCacheWithAliasKey(key, size, qValue);
if (image == NULL) {
if (next) {
// 责任链的下一个节点
image = next->query(key, size, qValue);
}
}
}
return image;
}
// 真正的实现在这里,子类继承
virtual Image *queryImage(char *key, Size size, int qValue) = 0;
Querier(Querier *next): _next(next) {}
private:
Querier *_next;
};
class QValueQuerier {
public:
Image *queryImage(char *key, Size size, int qValue) {
// 根据Q值查询
}
};
class ScacledImageQuerier {
public:
Image *queryImage(char *key, Size size, int qValue) {
// 查询等比图
// 裁剪
}
};
// 其它查询器
...
Querier *querierBuilder {
// 初始化缓存时构建查询链
Querier *querier = new QValueQuerier(new ScacledImageQuerier(xxx));
return querier;
}
// 查询
Image *getImage(char *key, Size size, int qValue) {
return querier->query(key, size, qValue);
}
通过对每种查询的抽象,封装出一个责任链模式的查询链路。看起来代码好像长了很多,但每个查询之间完全隔离,复杂度控制在查询内部。而对于图像缓存来说,它的抽象层所关心的是这个查询逻辑,并不关心每个查询具体的实现,所以对于它来说复杂度也很低,只在于查询链的构建。代码结构非常清晰,易维护,易扩展。
再聊责任链
责任链是一个非常常用的设计模式,老Y除了在上面的多媒体缓存中用到以外,还有一个场景也让其印象深刻。
当时在做支付宝的AR,这里仅讨论其中关于相机的处理部分,下图是一个典型的AR场景,画面上可能会有一些输入源,如相机画面、3D模型、水印、贴图等,画面也会有一些特效处理,比如美颜、前置相机的镜像等,最终画面可以预览到屏幕上,也可以保存到文件中。
最初的设计很简单,提供了一个ARCameraView,它的功能非常“全面”,能够控制相机、画面增加美颜、录制视频、渲染上屏等。对于使用者来说,看起来是比较简单的,只需要不停的设置属性,它像是一个Facade,所有的实现都在ARCameraView的内部处理。
有嗅到其中的坏味道吗?
看起来很简单也很直接对吧,可这个设计存在很多问题:
- 它的扩展性非常差,每新增一个能力,比如增加一个滤镜、特效等,都需要开放新的接口,最终这个ARCameraView将变得非常庞大,接口也很多;
- 对于业务方而言,想要自定义流程十分困难,因为很多逻辑都是固定的;
- 对于实现而言,ARCameraView的内部实现非常复杂,如果想改一下渲染的流程将大动干戈,shader的复杂度极高,濒临不可维护的状态。
于是在一个五一的假期,老Y铁了心将这个类进行了重构。思想参考了移动端有名的渲染框架GPUImage,将整体渲染链路抽象成一个责任链,每个节点只专注于自己的逻辑。并引入三个概念,Source、Functor与Output:
- Source是数据源,比如相机、图片、视频等,它们是数据的源头,产生数据给后面的节点进行消费;
- Functor类似于一个handler,它接收一个数据,处理完成后再输出一个数据,比如滤镜、美颜等能力;
- 最后的Output是输出结点,一般位于链路的最后,接收前面节点产生的数据,不再向后传递新的数据,比如录制、预览等。
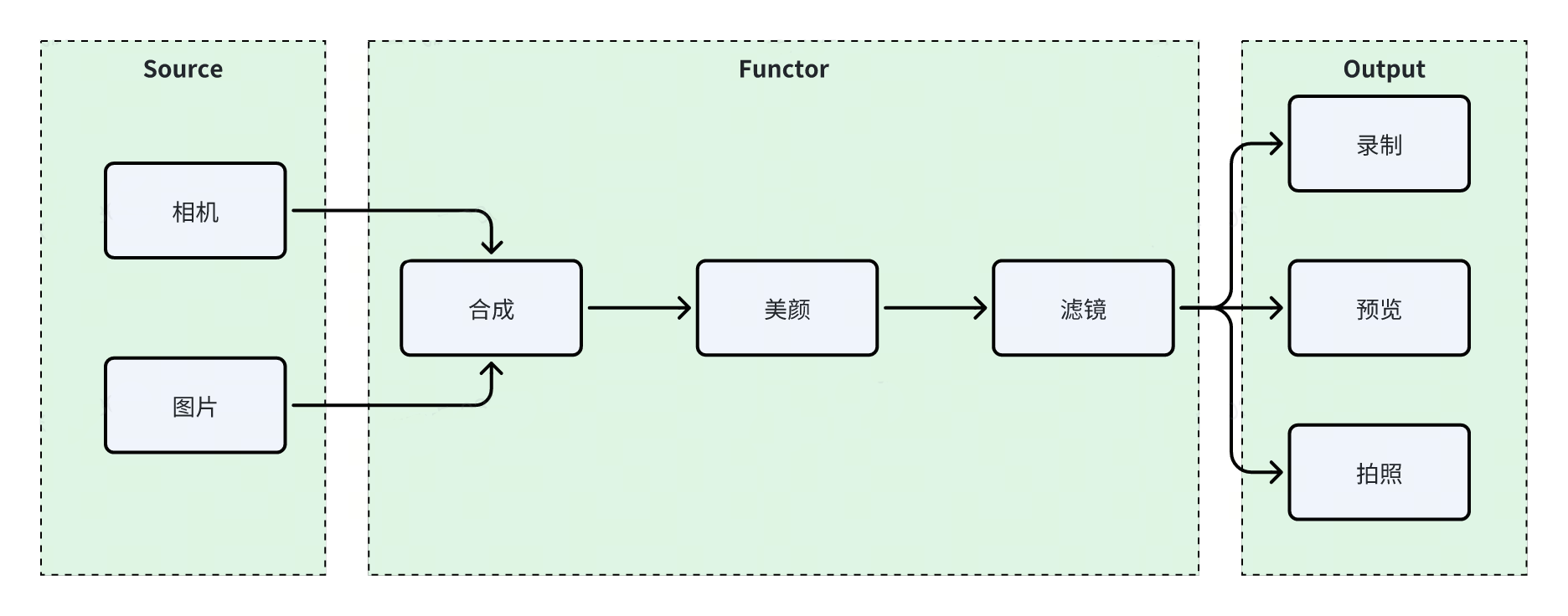
经过这样的抽象之后,ARCameraView的复杂度得到了显著的降低,可扩展性得到大幅提升,开放的接口也急剧减少,每种能力只需要关心自身内部的逻辑。业务侧在初始化时将这些能力组装成一条责任链,开启相机之后便开始加载数据。当新增一种能力时,比如抠像特效,只需要增加一个抠像的functor即可,业务层将它插入到链路中,现有的能力和链路不需要任何修改。
对了,关于给这个代码库取名老Y也极费心思。因为这里的整条链路都是在和GPU打交道,所以取名Texel,它本意是GPU纹理中的一个叫“纹素”的概念,对应于图像中的Pixel“像素”,老Y甚至后来还将它印到了球衣上。

状态机
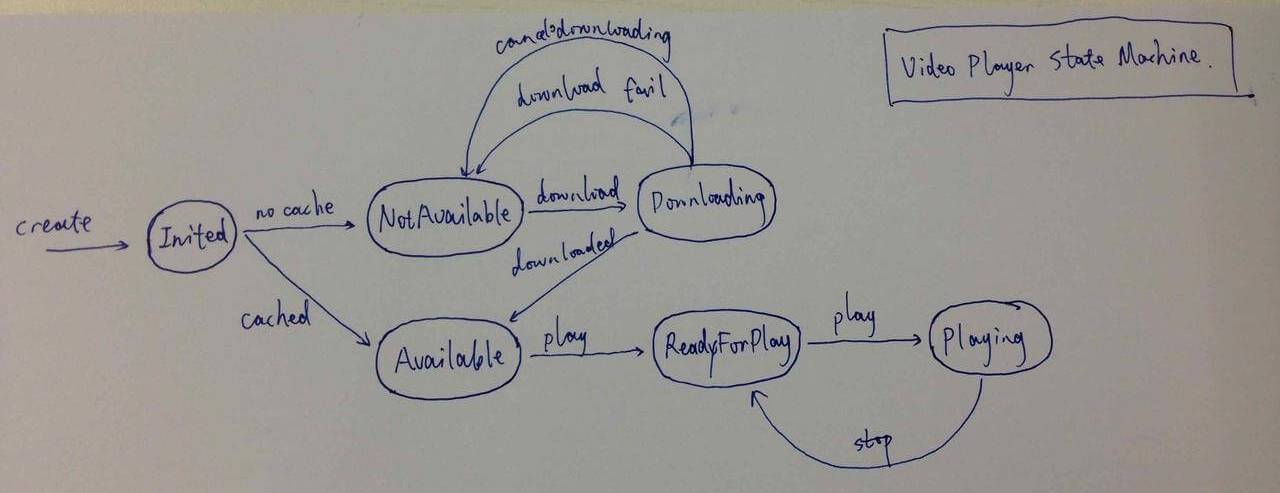
状态机是非常常见的一种设计模式,老Y曾在一个视频播放器的项目中使用过。因为是基于系统的AVPlayer进行封装,所以不需要涉及到播放器解码等更底层的能力。当时还没有在线播放的能力,仅仅是从服务端下载视频文件,下载完成后才可以播放。假如这里不用状态机,会怎么实现,比较直观的实现如下:
enum Status {
Inited,
NotAvailable,
Available,
...
};
void playVideo() {
switch (status) {
case Inited: {
// get video and play
break;
}
case NotAvailable: {
// downloadVideo and play
break;
}
case Available: {
// get video and play
break;
}
...
}
}
void downloadVideo() {
switch (status) {
case Inited: {
// get video
break;
}
case NotAvailable: {
// download
break;
}
case Available: {
// do nothing
break;
}
...
}
}
是否嗅到了“坏味道”?
没错,这就和前面的movie_data一样,每一个方法都包含了大量的状态分支,每种状态都要处理不同的逻辑,极其复杂。换一种思路来看,如果不是从事件出发,而是从状态出发来思考,每个状态应该响应不同的事件,播放器的状态也会随着不同事件的驱动而发生变化。那样每种状态就只用关心如何响应对应事件,以及会向哪个状态扭转。
找到了一张当年画的图,现在看起来还是很简单。再从本质上来看,状态机依然是在降低复杂度,它将状态内部的处理逻辑封装到一个类中,每个状态仅响应特定的事件,并且只知道它可能跳到哪个状态,对于其它的状态完全不用了解。而如果是采用过程式的处理方式,可能要在每个方法的内部增加判断,导致每个方法都变得很复杂。
老Y说:因为设计模式很多,经常会出现想到用某个设计模式可以实现这个功能,但是忘了该模式具体如何实现,此时可以再去翻翻设计模式的介绍。所以不需要完全记得所有设计模式的实现,更重要的是要知道每个设计模式可以解决什么问题。
随后的故事
老Y在随后的工作中还遇到了很多代码架构的设计工作,从AR到游戏引擎,从责任链到跨平台DSL调度框架,此时的问题已经不能用单一的设计模式解决,而是会大量的运用设计原则、设计模式的组合。但它们的本质是一样的,就是倾其所能来降低复杂度,如果将它们一一拆解下来,最终还是会回归到这些原则与模式当中。这里由于篇幅的原因,不再对后面的几个大型项目展开。
老Y说:架构能力是无数次绞尽脑汁的堆积,它是抽象能力与业务理解的结合。
谈谈业务开发与架构
很多同学是偏业务的开发,有时会自我调侃就是个画UI的,如何在这种类似“搬砖”的工作内容下提升自身的架构能力?
老Y想将业务的开发(也不仅是业务开发,所有开发都是如此)分成四个层次:
- 能打:王宝强的封于修,动作凶狠凌厉
- 又帅又能打:赵文卓的聂风、法海,不仅能打而且动作飘逸
- 又帅又能打又有内涵:李连杰的黄飞鸿,动作飘逸自不必说,更是一代宗师
- 又帅又能打又有内涵又有影响力:李小龙,让世界认识了中国功夫




第一个层次是开发的基本要求,保证需求高质量交付,完美实现需求文档。但在代码设计上考虑的比较少,功能能够正常运行少出bug。
第二个层次在层次一的基础上更进了一步,除高质量交付以外,它在代码设计上有更多的要求,千方百计让自己的代码更加优雅,具有可维护性、可扩展性,看着赏心悦目。小到一个变量的命名,大到整体框架的设计,都对自己提出了高要求,好似“洁癖”一般,不达到自己满意的程度就浑身难受。
层次三在二的基础上,会深入到使用的各种库,去了解它们的原理、设计,掌握之后在自己的开发中可以举一返三,可以说它是通往下个阶段必不可缺的。移动端开发有大量的优秀开源库,如iOS的SDWebImage、AFNetworking、Masonary、Lottie、YYCache等等。比如说SDWebImage,为什么要设计成多级缓存,它再和YYCache相比,淘汰策略有何不同,是否有更好的设计?它们都是将理论与实践结合起来最好的范例。开源代码是最好的学习材料,老Y从GPUImage中学了责任链,从mediapipe中学了Scheduler,从游戏引擎中学会大型框架的设计等。现在就可以行动起来,可以找一个自己常用的三方库,去看它的源码,画出UML与时序图,在掌握了理论之后,这是最好的学习架构的方式,没有之一。
最后一个层次是将自己开发过程中可复用的部分沉淀为SDK,甚至开源出去给到其它人使用。我们日常使用了大量的开源库,很多都是来自于在实际的开发过程中,将问题抽象到一定的层次,从而整理成一个专门的框架来处理类似的问题,继而开源,这方面的例子数不胜数,比如:
- Airbnb的lottie
- Facebook的react native和fishhook
- 微软的PLCrashReporter
- 阿里的Weex
- 微信的JSPatch
- …
这个层次要求会很高,它需要你对一个领域有比较深的理解以及出色的架构能力才可能做到。但可以先从自己的代码能够比较好的复用做起,可以是小到一个UI组件的复用,比如一个特定场景的控件,也可以是大到一个动画框架如Lottie,关键是锻炼这种思维。不积跬步,无以至千里。
老Y说:最好的代码架构是重构出来的,并不是一蹴而就,所以在刚开始不需要过度设计,去考虑未来很多年的变化。当业务越来越复杂,人们不再满足于当下的设计,根据对业务的理解逐渐迭代架构以满足当下与将来的需求,必要时可能全部推翻重来。
写在最后
即使读过一百本书,听过无数次分享,可能不经历过一次就无法真正的学会一件事,人的大脑好像会对这些不产生于自身的道理天生就持抵制态度一样,“我知道”与“我真的知道”之间隔着一道必须通过亲身经历才能跨越的鸿沟。架构亦是如此,关于架构的著作读起来有时会让人觉得过于高屋建瓴,有时会全面又深入细节,如果没有实践的支撑,很多理论难以产生共鸣。所以开发者必须长期战斗在编码一线,不断去思考、总结、沉淀,没有谁能够仅凭理论就拥有不错的架构能力。
以上这些经历正是老Y在编码路上一次次既痛苦又兴奋的时刻,从架构设计的角度来说,这些观点既不全面,也可能有失偏颇,甚至它们仅仅停留在代码设计的层面,远未谈到架构。对于大部分人来说,这些经历也过于稀松平常。如文章开头所问,为何还要写?
对于老Y来说,每一次经历都对他理解架构产生了深远的影响,所以即便过去多年,它们依然历历在目,就像乔布斯所说的Collecting the dots,在未来的某一刻它们可能会发挥意想不到的作用。对于文章前的你,这些经历能够展示出老Y在面对这些设计问题时如何思考,对初窥架构之门的你也许会有所启发,帮助你找到属于自己的那些烙印时刻,因此成文。
(全文完)
feihu
2024.03.06 于 Shenzhen
一点推荐
源码
源代码是最好的学习代码架构的方式,没有之一,这里仅列举几个,以浅到深,大家可以选择阅读。同时,大家可以直接看开发过程中经常使用的三方库,找到其源码,以及一些源码剖析的文章结合着看,会比较高效。
- AFNetworking:iOS平台有名的网络框架
- GPUImage:移动端有名的链式GPU渲染框架
- YYCache:iOS平台上的多级高性能缓存
- ARKit:Apple的ARKit框架
- CppUnit:C++的单元测试框架,短小精干的框架,体现了很多代码设计的思考
- Mediapipe:Google的跨平台机器学习框架
- Git:可以看Linus撸出来的第一个版本
- GamePlay3D:跨平台的小型游戏引擎,但五脏俱全
书
再来推荐几本和架构有关的经典书籍:
- 《设计模式》:四人帮关于设计模式的鼻祖,不过太干以致于看起来有点枯燥,可作为手册,结合下面的HeadFirst一起看
- 《HeadFirst设计模式》:更加浅显易懂,推荐这本
- 《重构》:给了大量的范例,手把手教你如何进行代码重构
- 《代码整洁之道》和《架构整洁之道》:关于追求极致代码和架构的两本书,后者的推荐序是刚刚离开的左耳朵耗子
- 《代码大全》:和架构关系不大,但逢人必推,它是从学校迈入职场必读的一本书